| Впервые на русском языке книга о QNX. Роб Кертен "Введение в QNX/Neutrino 2". Аннотация, Заказ печатной версии(400 р.) |
Книга Системная архитектура сопровождает операционную систему QNX и предназначена как для разработчиков приложений, так и для конечных пользователей.
В книге подробно рассматривается структура и функции QNX. В ней описаны микроядро, системные менеджеры, а также уникальный механизм связи между процессами, основанный на передаче сообщений. Прежде чем использовать QNX, рекомендуется сначала прочитать эту книгу.
За информацией об установке и использовании QNX, обратитесь к книге Руководство пользователя ОС QNX
Системная архитектура содержит следующие главы:
Эта глава охватывает следующие темы:
Главная обязанность операционной системы состоит в управлении ресурсами компьютера. Все действия в системе - диспетчеризация прикладных программ, запись файлов на диск, пересылка данных по сети и т.п. - должны выполняться совместно настолько слитно и прозрачно, насколько это возможно.
Некоторые области применения предъявляют более жесткие требования к управлению ресурсами и диспетчеризации программ, чем другие. Приложения реального времени, например, полагаются на способность операционной системы обрабатывать многочисленные события в пределах ограниченного интервала времени. Чем быстрее реагирует операционная система, тем большее пространство для маневра имеет приложение реального времени в пределах жестких временных рамок.
Операционная система QNX идеальна для приложений реального времени. Она обеспечивает все неотъемлемые составляющие системы реального времени: многозадачность, диспетчеризацию программ на основе приоритетов и быстрое переключение контекста.
QNX - удивительно гибкая система. Разработчики легко могут настроить операционную систему таким образом, чтобы она отвечала требованиям конкретных приложений. QNX позволяет вам создать систему, использующую только необходимые для решения вашей задачи ресурсы. Конфигурация системы может изменяться в широком диапазоне - от ядра с несколькими небольшими модулями до полноценной сетевой системы, обслуживающей сотни пользователей.
QNX достигает своего уникального уровня производительности, модульности и простоты благодаря двум фундаментальным принципам:
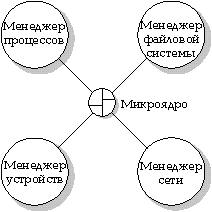
QNX состоит из небольшого ядра, координирующего работу взаимодействующих процессов. Как показано на рисунке, структура больше напоминает не иерархию, а команду, в которой несколько игроков одного уровня взаимодействуют между собой и со своим "защитником" - ядром.
Микроядро системы QNX координирует работу системных менеджеров.
Ядро - это "сердце" любой операционной системы. В некоторых операционных системах на него возлагается так много функций, что ядро, по сути, заменяет всю операционную систему!
В QNX же Микроядро - это настоящее ядро. Во-первых, как и следует ядру реального времени, ядро QNX имеет очень маленький размер. Во-вторых, оно выполняет две важнейшие функции:
В отличие от всех остальных процессов, ядро никогда не получает управления в результате диспетчеризации. Входящий в состав ядра код выполняется только в результате прямых вызовов из процесса или аппаратного прерывания.
Все услуги операционной системы, за исключением тех, которые выполняются ядром, в QNX предоставляются через стандартные процессы. Типичная конфигурация QNX имеет следующие системные процессы:
Системные процессы практически ничем не отличаются от любых написанных пользователем программ - они не имеют какого-либо скрытого или особого интерфейса, недоступного пользовательским процессам.
Именно за счет такой системной архитектуры QNX обладает уникальной наращиваемостью. Так как большинство услуг операционной системы предоставляются стандартными процессами QNX, то расширение операционной системы требует всего лишь написания новой программы, обеспечивающей новую услугу!
Фактически, граница между операционной системой и прикладной программой может быть очень размыта. Единственный критерий, по которому мы можем отличить прикладные процессы и системные сервисные процессы, состоит в том, что процесс операционной системы управляет каким-либо ресурсом в интересах прикладного процесса.
Предположим, что вы написали сервер базы данных. Как же должен быть классифицирован этот процесс?
Точно так же, как сервер файловой системы принимает запросы (в QNX реализованные через механизм сообщений) на открытие файлов и запись или чтение данных, это будет делать и сервер базы данных. Хотя запросы к серверу базы данных могут быть и более сложными, сходство обоих серверов заключается в том, что оба они обеспечивают доступ к ресурсу посредством запросов. Оба они являются независимыми процессами, которые могут быть написаны пользователем и запускаться по мере необходимости.
Сервер базы данных может рассматриваться как процесс в одном случае и как приложение в другом. Это действительно не имеет значения! Важно то, что создание и выполнение таких процессов в QNX не требует абсолютно никаких изменений в стандартных компонентах операционной системы.
Драйверы устройств - это процессы, которые являются посредниками между операционной системой и устройствами и избавляют операционную систему от необходимости иметь дело с особенностями конкретных устройств.
Так как драйверы запускаются как обычные процессы, добавление нового драйвера в QNX не влияет на другие части операционной системы. Таким образом, добавление нового драйвера в QNX не требует ничего, кроме непосредственно запуска этого драйвера.
После запуска и завершения процедуры инициализации, драйвер может выбрать один из двух вариантов поведения:
В типичной для многозадачной системы реального времени ситуации, когда несколько процессов выполняются одновременно, операционная система должна предоставить механизмы, позволяющие им общаться друг с другом.
Связь между процессами (Interprocess communication, сокращенно IPC) является ключом к разработке приложений как совокупности процессов, в которых каждый процесс выполняет отведенную ему часть общей задачи.
QNX предоставляет простой, но мощный набор возможностей IPC, которые существенно облегчают разработку приложений, состоящих из взаимодействующих процессов.
QNX была первой коммерческой операционной системой своего класса, которая использовала передачу сообщений в качестве основного способа IPC. Именно последовательное воплощение метода передачи сообщения в масштабах всей операционной системы обусловливает мощность, простоту и элегантность QNX.
Сообщения в QNX - это последовательность байт, передаваемых от одного процесса другому. Операционная система не пытается анализировать содержание сообщения - передаваемые данные имеют смысл только для отправителя и получателя, и ни для кого более.
Передача сообщения позволяет не только обмениваться данными, но и является способом синхронизации выполнения нескольких процессов. Когда они посылают, получают или отвечают на сообщения, процессы претерпевают различные "изменения состояния", которые влияют на то, когда и как долго они могут выполняться. Зная состояния и приоритеты процессов, ядро организует их диспетчеризацию таким образом, чтобы максимально эффективно использовать ресурсы центрального процессора (ЦП).
Приложение реального времени и другие ответственные приложения по праву нуждаются в надежном механизме передачи сообщений, т.к. входящие в состав этих приложений процессы тесно взаимосвязаны. Реализованный в QNX механизм передачи сообщений способствует упорядочению и повышению надежности программ.
В простейшем случае локальная сеть обеспечивает разделяемый доступ к файлам и периферийным устройствам для нескольких соединенных между собой компьютеров. QNX идет гораздо дальше этого простейшего представления и объединяет всю сеть в единый однородный набор ресурсов.
Любой процесс на любом компьютере в составе сети может непосредственно использовать любой ресурс на любом другом компьютере. С точки зрения приложений, не существует никакой разницы между местным или удаленным ресурсом, и использование удаленных ресурсов не требует каких-либо специальных средств. Более того, чтобы определить, находится ли такой ресурс как файл или устройство на локальном компьютере или на другом узле сети, в программу потребуется включить специальный дополнительный код!
Пользователи могут иметь доступ к файлам по всей сети, использовать любое периферийное устройство, запускать программы на любом компьютере сети (при условии, что они имеют надлежащие полномочия). Связь между процессами осуществляется единообразно, независимо от их местоположения в сети. В основе такой прозрачной поддержки сети в QNX лежит всеобъемлющая концепция IPC на основе передачи сообщений.
QNX изначально проектировался как сетевая операционная система. В некоторых отношениях QNX сеть напоминает скорее большую ЭВМ, нежели набор мини-компьютеров. Пользователям известно, что в распоряжении любой из прикладных программ имеется большой набор ресурсов. Но в отличие от большой ЭВМ, QNX обеспечивает быструю реакцию системы, т.к. соответствующий объем вычислительных ресурсов может быть выделен на каждом узле в соответствии с потребностями каждого пользователя.
В условиях управления производством используются программируемые контроллеры и другие устройства ввода/вывода, а также комплексы программ, работающие в режиме реального времени, которым может потребоваться больше ресурсов, чем другим менее ответственным приложениям, таким как текстовый редактор. Сеть QNX достаточно "отзывчива", чтобы поддерживать одновременно оба этих типа приложений, QNX позволяет сфокусировать вычислительную мощность системы на производственном оборудовании (там, где это необходимо), в то же время, не жертвуя интерфейсом пользователя.
QNX сеть может быть построена с использованием различного оборудования и стандартных промышленных протоколов. В силу своей полной прозрачности для прикладных программ и пользователей, новые сетевые архитектуры могут быть внедрены в любое время, не разрушая операционной системы.
| Список поддерживаемого QNX сетевого оборудования пополняется со временем. Для получения подробной информации обратитесь к документации на сетевое оборудование, которое вы используете. |
Каждому узлу QNX сети присваивается уникальный номер, который становится его идентификатором. Этот номер также единственный видимый признак того, функционирует QNX как сеть или как однопроцессорная операционная система.
Такая степень прозрачности является еще одним примером больших возможностей архитектуры QNX, основанной на передаче сообщений. Во многих операционных системах такие важные функции как поддержка сети, IPC или даже передача сообщений выполнены в виде надстроек над операционной системой, а не интегрированы непосредственно в ее сердцевину. Результатом такого подхода является неуклюжий и неэффективный интерфейс с "двойным стандартом", когда связь между процессами - это одно дело, в то время как проникновение в скрытый интерфейс таинственного монолитного ядра - совершенно другое дело!
QNX, напротив, исходит из того, что эффективная связь является ключом к эффективной работе. Передача сообщений является, таким образом, краеугольным камнем архитектуры QNX, увеличивает эффективность всех без исключения транзакций между процессами в системе, независимо от того, идет ли речь о передаче данных по внутренней шине персонального компьютера или по коаксиальному кабелю на расстояние нескольких миль.
Теперь давайте перейдем к более подробному рассмотрению структуры QNX.
Эта глава охватывает следующие темы:
Микроядро QNX отвечает за выполнение следующих функций:
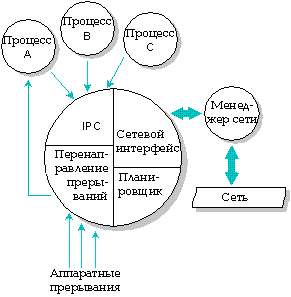
Внутри микроядра QNX.
Микроядро QNX поддерживает три важнейшие формы связи между процессами: сообщения, прокси и сигналы.
Сообщения в QNX - это пакеты байт, которые синхронно передаются от одного процесса к другому. QNX при этом не анализирует содержание сообщения. Передаваемые данные понятны только отправителю и получателю и никому более.
Для непосредственной связи друг с другом взаимодействующие процессы используют следующие функции языка программирования Си:
| Функция языка Си: | Назначение: |
|---|---|
| Send() | посылка сообщений |
| Receive() | получение сообщений |
| Reply() | ответ процессу, пославшему сообщение |
Эти функции могут быть использованы как локально, т.е. для связи между процессами на одном компьютере, так и в пределах сети, т.е. для связи между процессами на разных узлах.
Следует заметить, однако, что далеко не всегда возникает необходимость использовать функции Send(), Receive() и Reply() в явном виде. Библиотека функций языка Си в QNX построена на основе использования сообщений - в результате, когда процесс использует стандартные механизмы передачи данных (такие, как, например, программный канал - pipe), он косвенным образом использует передачу сообщений.
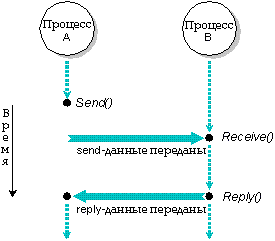
Процесс A посылает сообщение процессу B, который получает его, обрабатывает и посылает ответ
На рисунке изображена последовательность событий, имеющих место, когда два процесса, процесс A и процесс B, используют функции Send(), Receive() и Reply() для связи друг с другом:
Заметьте, что если бы процесс B вызвал Receive() до того, как ему было послано сообщение, то он бы попал в состояние RECEIVE-блокирован до получения сообщения. В этом случае процесс-отправитель сообщения немедленно после посылки сообщения попал бы в состояние REPLY-блокирован.
Передача сообщений не только позволяет процессам обмениваться данными, но и предоставляет механизм синхронизации выполнения нескольких взаимодействующих процессов.
Давайте снова рассмотрим приведенный выше рисунок. После того как процесс A вызвал функцию Send(), он не может продолжать выполнение до тех пор, пока не получит ответ на посланное сообщение. Это гарантирует, что выполняемая процессом B по запросу процесса A обработка данных будет завершена прежде, чем процесс A продолжит выполнение. Более того, после вызова процессом B запроса на получение данных Receive(), он не может продолжать выполнение до тех пор, пока не получит следующее сообщение.
| Более подробно диспетчеризация процессов в QNX рассматривается в разделе "Диспетчеризация процессов" далее в этой главе. |
Когда процессу не разрешается продолжать выполнение, т.к. он должен ожидать окончания определенной стадии протокола передачи сообщения, - процесс называется блокированным.
Возможные блокированные состояния процессов приведены в следующей таблице:
| Если процесс выдал: | То процесс: |
|---|---|
| Запрос Send(), и отправленное им сообщение еще не получено процессом-получателем | SEND-блокирован |
| Запрос Send(), и отправленное им сообщение получено процессом-получателем, но ответ еще не выдан | REPLY-блокирован |
| Запрос Receive(), но еще не получил сообщение | RECEIVE-блокирован |
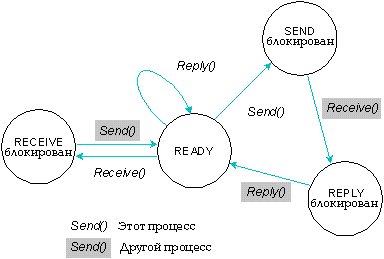
Изменение состояния процессов в типичном случае передачи сообщения.
| Для получения информации обо всех возможных состояниях процесса смотри главу "Менеджер процессов". |
Использование Send(), Receive() и Reply()
Давайте теперь более подробно рассмотрим вызовы функций Send(), Receive() и Reply(). Воспользуемся рассмотренным выше примером передачи сообщения от процесса A к процессу B.
Предположим, что процесс А выдает запрос на передачу сообщения процессу В. Это выполняется посредством вызова функции Send():
Send( pid, smsg, rmsg, smsg_len, rmsg_len );
При вызове функции Send() используются следующие аргументы:
Обратите внимание, что будет передано не более smsg_len байт и не более чем rmsg_len байт будет получено в качестве ответа - это гарантирует, что не произойдет случайного переполнения буферов.
Вызвав запрос Receive(), процесс B может получить сообщение, направленное ему процессом A:
pid = Receive( 0, msg, msg_len )
Вызов функции Receive() содержит следующие аргументы:
Если значения аргументов smsg_len в вызове функции Send() и msg_len в вызове функции Receive() отличаются, друг от друга, то наименьшее из них определяет размер данных, которые будут переданы.
После успешного получения сообщения от процесса A, процесс B должен ответить процессу A, вызвав функцию Reply():
Reply( pid, reply, reply_len );
Вызов функции Reply() содержит следующие аргументы:
Если значения аргументов reply_len при вызове функции Reply() и rmsg_len при вызове функции Send() отличаются друг от друга, то наименьшее из них определяет размер передаваемых данных.
Reply-управляемый обмен сообщениями
Пример обмена сообщениями, который мы только что рассмотрели, иллюстрирует наиболее распространенный случай использования сообщений - случай, когда для процесса, выполняющего функции сервера, нормальным является состояние RECEIVE-блокирован в ожидании каких-либо запросов клиента. Это называется send-управляемый обмен сообщениями: процесс-клиент инициирует действие, посылая сообщения, ответ сервера на сообщение завершает действие.
Существует и другая модель обмена сообщениями, не столь распространенная, как рассмотренная выше, хотя в некоторых ситуациях она даже более предпочтительна: reply-управляемый обмен сообщениями, при котором действие инициируется вызовом функции Reply(). В этом случае процесс-"работник" посылает серверу сообщение, говорящее о том, что он готов к работе. Сервер не отвечает сразу, а "запоминает", что работник готов выполнить его задание. В последствии сервер может инициировать действие, ответив ожидающему задание работнику. Процесс-работник выполнит задание и завершит действие, послав серверу сообщение, содержащее результаты своей работы.
При разработке программ, использующих передачу сообщений, необходимо иметь в виду следующее:
Несмотря на такую кажущуюся простоту, вызов функции Send() делает гораздо больше, чем простой вызов библиотечной подпрограммы. Функция Send() может прозрачно для вызывающей программы передать запрос на другой узел сети, где и будет в действительности выполняться обслуживающий запрос код. При этом также может быть задействована параллельная обработка данных без издержек на создание нового процесса. Процесс-сервер может сразу, как только станет возможным, вызвать функцию Reply(), позволяя тем самым запрашивавшему процессу возобновить выполнение и, в то же время, продолжить выполнение самому.
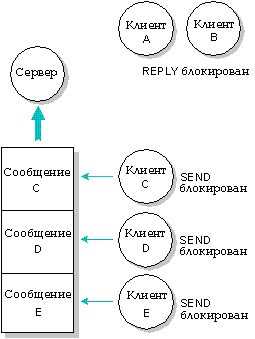
Сервер получил сообщение от клиента A и клиента B (но еще не ответил им). Сообщения от клиентов C, D, E еще не получены.
QNX также предоставляет следующие дополнительные возможности по передаче сообщений:
Обычно, когда процесс хочет принять сообщение, он вызывает функцию Receive() для ожидания прихода сообщения. Это обычный способ получения сообщений, который пригоден в большинстве случаев.
Однако возможна ситуация, когда процессу необходимо определить, имеются ли ожидающие приема сообщения, не попадая при этом в состояние RECEIVE-блокирован в случае их отсутствия. Например, процессу требуется опрашивать работающее с высокой скоростью устройство, которое не способно генерировать прерывание, и в то же время он должен отвечать на сообщения от других процессов. В этом случае процесс может использовать функцию Creceive(), которая либо прочитает ожидающее приема сообщение, либо немедленно вернет управление процессу в случае отсутствия ожидающих приема сообщений.
| Следует по возможности избегать использования функции Creceive(), т.к. она позволяет процессу непрерывно выполняться с неизменяющимся уровнем приоритета. |
Иногда желательно читать или записывать сообщения по частям с тем, чтобы использовать уже выделенный для сообщения буфер вместо выделения отдельного рабочего буфера.
Например, менеджер ввода/вывода может принимать данные в виде сообщений, которые состоят из заголовка фиксированной длины и следующих за ним данных переменной длины. В заголовке указывается размер данных (от 0 до 64 Кбайт). В этом случае менеджер ввода/вывода может сначала принять только заголовок сообщения, а затем использовать функцию Readmsg() для чтения данных переменной длины непосредственно в соответствующий буфер вывода. Если размер данных превышает размер буфера, то менеджер может неоднократно вызывать функцию Readmsg() по мере освобождения буфера вывода. Аналогичным образом, функция Writemsg() может быть использована для поэтапного копирования данных в выделенный для ответного сообщения буфер непосредственно в теле процесса, пославшего сообщение, уменьшая, таким образом, потребность менеджера ввода/вывода в выделении внутренних буферов.
До сих пор мы рассматривали сообщения как непрерывную последовательность байт. Однако сообщения часто состоят из двух или более отдельных частей. Например, сообщение может иметь заголовок фиксированной длины, за которым следуют данные переменной длины. Для того чтобы избежать копирования частей такого сообщения во временные промежуточные буферы при передаче или приеме, может быть использовано составное сообщение, состоящее из двух или более отдельных буферов сообщений. Именно благодаря этой возможности менеджеры ввода/вывода QNX, такие как Dev и Fsys, достигают своей высокой производительности.
Следующие функции позволяют обрабатывать составные сообщения:
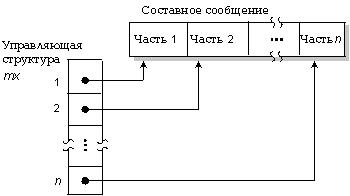
Составные сообщения могут быть описаны с помощьюqqq?0 специальной mx структуры. Микроядро объединяет части такого сообщения в единый непрерывный поток данных.
Зарезервированные коды сообщений
QNX начинает все сообщения с 16-ти битного слова, называемого кодом сообщения. Заметим, однако, что это не является обязательным для вас требованием при написании собственных программ. QNX использует коды сообщений в следующих диапазонах:
| Зарезервированный диапазон: | Описание: |
|---|---|
| 0x0000 - 0x00FF | Сообщения Менеджера процессов |
| 0x0100 - 0x01FF | Сообщения ввода/вывода (общие для всех серверов ввода/вывода) |
| 0x0200 - 0x02FF | Сообщения Менеджера файловой системы |
| 0x0300 - 0x03FF | Сообщения Менеджера устройств |
| 0x0400 - 0x04FF | Сообщения Менеджера сети |
| 0x0500 - 0x0FFF | Зарезервированы для будущих системных процессов QNX |
Прокси - это форма неблокирующего сообщения, особенно подходящего для извещения о наступлении события, когда посылающий процесс не нуждается в диалоге с получателем. Единственная функция прокси состоит в посылке фиксированного сообщения определенному процессу, который является владельцем прокси. Подобно сообщениям, прокси могут быть использованы в пределах всей сети.
Используя прокси, процесс или обработчик прерывания может послать сообщение другому процессу, не блокируясь и не ожидая ответа.
Вот некоторые примеры использования прокси:
Для создания прокси используется функция языка Си qnx_proxy_attach(). Любой другой процесс или обработчик прерывания, которому известен идентификатор прокси, может воспользоваться функцией языка Си Trigger() для того, чтобы заставить прокси передать заранее заданное сообщение. Запрос Trigger() обрабатывается Микроядром.
Прокси может быть "запущено" неоднократно - каждый раз при этом оно посылает сообщение. Прокси может накапливать очередь длиной до 65535 сообщений.
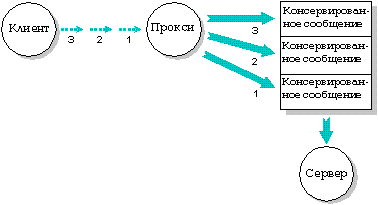
Процесс-клиент запускает прокси 3 раза, в результате чего сервер получает 3 "консервированных" сообщения от прокси.
Сигналы являются традиционным способом асинхронной связи, которая используется в течение многих лет в различных операционных системах.
QNX поддерживает большой набор сигналов, соответствующих стандарту POSIX, кроме того, сигналы, исторически присущие некоторым UNIX-системам, и ряд сигналов, уникальных для QNX.
Считается, что сигнал доставлен процессу тогда, когда выполняется определенное в процессе для данного сигнала действие. Процесс может посылать сигнал самому себе.
| Если вы хотите: | Используйте: |
|---|---|
| Породить сигнал из командной строки | Утилиты: kill и slay |
| Породить сигнал внутри процесса | Функции Си: kill() и raise() |
Процесс может принять сигнал одним из трех способов, в зависимости от того, как в процессе определена обработка сигналов:
В промежутке времени между моментом, когда сигнал порожден, и моментом, когда он доставлен, сигнал называется ожидающим. Для процесса ожидающими одновременно могут быть несколько различных сигналов. Сигналы доставляются процессу, когда планировщик ядра делает этот процесс готовым к выполнению. Процесс не должен строить никаких предположений относительно порядка, в котором будут доставлены ожидающие сигналы.
| Сигнал: | Описание: |
|---|---|
| SIGABRT | Сигнал ненормального завершения, порождается функцией abort(). |
| SIGALRM | Сигнал тайм-аута, порождается функцией alarm(). |
| SIGBUS | Указывает на ошибку контроля четности оперативной памяти (особая для QNX интерпретация). Если во время выполнения обработчика данного сигнала произойдет вторая такая ошибка, то процесс будет завершен. |
| SIGCHLD | Завершение порожденного процесса. Действие по умолчанию - игнорировать сигнал. |
| SIGCONT | Если процесс в состоянии HELD, то продолжить выполнение. Действие по умолчанию - игнорировать сигнал, если процесс не в состоянии HELD. |
| SIGDEV | Генерируется, когда в Менеджере устройств происходит важное и запрошенное событие. |
| SIGFPE | Ошибочная арифметическая операция (целочисленная или с плавающей запятой), например, деление на ноль или операция, вызвавшая переполнение. Если во время выполнения обработчика данного сигнала произойдет вторая такая ошибка, то процесс будет завершен. |
| SIGHUP | Гибель процесса, который был ведущим сеанса, или зависание управляющего терминала. |
| SIGILL | Обнаружение недопустимой аппаратной команды. Если во время выполнения обработчика данного сигнала произойдет вторая такая ошибка, то процесс будет завершен. |
| SIGINT | Интерактивный сигнал "внимание" (Break) |
| SIGKILL | Сигнал завершения - должен быть использован только в экстренных ситуациях. Этот сигнал не может быть "пойман" или игнорирован. Сервер может защитить себя от этого сигнала посредством функции языка Си qnx_pflags(). Для этого сервер должен иметь статус привилегированного пользователя. |
| SIGPIPE | Попытка записи в программный канал, который не открыт для чтения. |
| SIGPWR | Перезапуск компьютера в результате нажатия Ctrl-Alt-Shift-Del или вызова утилиты shutdown. |
| SIGQUIT | Интерактивный сигнал завершения. |
| SIGSEGV | Обнаружение недопустимой ссылки на оперативную память. Если во время выполнения обработчика данного сигнала произойдет вторая такая ошибка, то процесс будет завершен. |
| SIGSTOP | Сигнал приостановки выполнения (HOLD) процесса. Действие по умолчанию - приостановить процесс. Сервер может защитить себя от этого сигнала посредством функции языка Си qnx_pflags(). Для этого сервер должен иметь статус привилегированного пользователя. |
| SIGTERM | Сигнал завершения. |
| SIGTSTP | Не поддерживается QNX. |
| SIGTTIN | Не поддерживается QNX. |
| SIGTTOU | Не поддерживается QNX. |
| SIGUSR1 | Зарезервирован как определяемый приложением сигнал 1. |
| SIGUSR2 | Зарезервирован как определяемый приложением сигнал 2. |
| SIGWINCH | Изменился размер окна. |
Управление обработкой сигналов
Чтобы задать желаемый способ обработки для каждого из сигналов, вы можете использовать функции языка Си signal() стандарта ANSI или sigaction() стандарта POSIX.
Функция sigaction() предоставляет большие возможности по управлению обработкой сигналов.
Вы можете изменить способ обработки сигнала в любой момент времени. Если вы укажете, что сигнал данного типа должен игнорироваться, то все ждущие сигналы такого типа будут немедленно отброшены.
Некоторые специальные замечания касаются процессов, которые ловят сигналы посредством обработчиков сигналов.
Вызов обработчика сигнала аналогичен программному прерыванию. Он выполняется асинхронно по отношению к остальной части процесса. Таким образом, существует вероятность того, что обработчик сигнала будет вызван во время выполнения любой из имеющихся в программе функций (включая библиотечные функции).
Если в вашей программе не предусмотрен возврат из обработчика сигнала, то могут быть использованы функции siglongjmp() либо longjmp() языка Си, однако, функция siglongjmp() предпочтительнее. При использовании функции longjmp() сигнал остается блокированным.
Иногда может возникнуть необходимость временно запретить получение сигнала, не изменяя метод его обработки. QNX предоставляет набор функций, которые позволяют блокировать получение сигналов. Блокированный сигнал остается ожидающим; после разблокирования он будет доставлен вашей программе.
Пока ваша программа выполняет обработчик сигнала для определенного типа сигнала, QNX автоматически блокирует этот сигнал. Это означает, что нет необходимости заботиться о вложенных вызовах обработчика сигнала. Каждый вызов обработчика сигнала - это неделимая операция по отношению к доставке следующих сигналов этого типа. Если ваш процесс выполняет нормальный возврат из обработчика, сигнал автоматически разблокируется.
| Реализация обработчиков сигналов в некоторых UNIX системах отличается тем, что при получении сигналов они не блокируют его, а устанавливают действие по умолчанию. В результате некоторые UNIX приложения вызывают функцию signal() изнутри обработчика сигналов, чтобы подготовить обработчик к следующему вызову. Такой способ имеет два недостатка. Во-первых, если следующий сигнал поступает, когда ваша программа уже выполняет обработчик сигнала, но еще не вызвала функцию signal(), то программа может быть завершена. Во-вторых, если сигнал поступает сразу после вызова функции signal() в обработчике, то возможен рекурсивный вход в обработчик сигнала. QNX поддерживает блокирование сигналов и, таким образом, не страдает ни от одного из этих недостатков. Вам не нужно вызывать функцию signal() изнутри обработчика сигналов. Если вы покидаете обработчик через дальний переход (long jump), вам следует использовать функцию siglongjmp(). |
Существует важное взаимодействие между сигналами и сообщениями. Если ваш процесс SEND-блокирован или RECEIVE-блокирован в момент получения сигнала, и вы предусмотрели обработчик сигнала, происходят следующие действия:
Если процесс был SEND-блокирован в момент получения сигнала, то проблемы не возникает, потому что получатель еще не получил сообщение. Но если процесс был RECEIVE-блокирован, то вы не узнаете, было ли обработано посланное им сообщение и, следовательно, не будете знать, следует ли повторять Send().
Процесс, играющий роль сервера (т.е. получающий сообщения), может запросить, чтобы он получал извещение всякий раз, когда его процесс-клиент получает сигнал, находясь в состоянии REPLY-блокирован. В этом случае клиент становится SIGNAL-блокированным с ожидающим сигналом. Сервер получает специальные сообщения, описывающие тип сигнала. Сервер может затем выбрать один из следующих вариантов:
ИЛИ
Когда сервер отвечает процессу, который был SIGNAL-блокирован, то сигнал выдается непосредственно после возврата из функции Send(), вызванной клиентом (процессом-отправителем).
Приложение в QNX может общаться с процессом на другом компьютере сети точно так же, как если бы оно общалось с другим процессом на том же самом компьютере. Кстати говоря, с точки зрения приложения нет различия между локальным и удаленным ресурсом.
Такая замечательная степень прозрачности становится возможна благодаря виртуальным каналам (от английского virtual circuit, сокращенно VC). VC - это пути, которые Менеджер сети предоставляет для передачи сообщений, прокси и сигналов по сети. VC способствуют эффективному использованию QNX-сети в целом по нескольким причинам:
Процесс-отправитель отвечает за подготовку VC между собой и тем процессом, с которым он хочет установить связь. С этой целью процесс-отправитель обычно вызывает функцию qnx_vc_attach(). Кроме создания VC, эта функция также создает на каждом конце канала виртуальный идентификатор процесса, сокращенно VID. Для каждого из процессов, VID на противоположном конце виртуального канала является идентификатором удаленного процесса, с которым он устанавливает связь. Процессы поддерживают связь друг с другом посредством этих VID.
Например, на следующем рисунке виртуальный канал соединяет PID 1 и PID 2. На узле 20 - где находится PID 1 - VID представляет PID 2. На узле 40 - где находится PID 2 - VID представляет PID 1. И PID 1 и PID 2 могут обращаться к VID на своем узле так же, как к любому другому локальному процессу, посылая сообщения, принимая сообщения, поставляя сигналы, ожидая и т.д. Так, например, PID 1 может послать сообщение VID на своем конце, и этот VID передаст сообщение по сети к VID, представляющему PID 1 на другом конце. Этот VID затем отправит сообщение к PID 2.
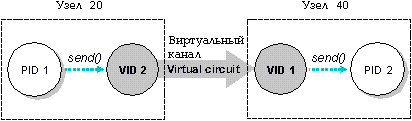
Связь по сети реализуется посредством виртуальных каналов. Когда PID 1 посылает данные VID 2, посланный запрос передается по виртуальному каналу, в результате VID 1 направляет данные PID 2.
Каждый VID поддерживает соединение, которое имеет следующие атрибуты:
Возможно, вам не придется часто иметь дело непосредственно с VC. Так, например, когда приложение хочет получить доступ к ресурсу ввода/вывода на другом узле сети, то VC создается библиотечной функцией open() от имени приложения. Приложение не принимает непосредственного участия в создании или использовании VC. Аналогичным образом, когда приложение определяет местонахождение сервера с помощью функции qnx_name_locate(), то VC автоматически создается от имени приложения. Для приложения VC просто является PID сервера.
Для более подробной информации о функции qnx_name_locate() смотрите описание "Символические имена процессов в главе "Менеджер процессов".
Виртуальное прокси позволяет посылать прокси с удаленного узла, подобно тому, как виртуальный канал позволяет процессу обмениваться сообщениями с удаленным узлом.
В отличие от виртуального канала, который связывает вместе два процесса, виртуальный прокси может быть послан любым процессом на удаленном узле.
Виртуальные прокси создаются функцией qnx_proxy_rem_attach(), которой в качестве аргументов передаются узел (nid_t) и прокси (pid_t).
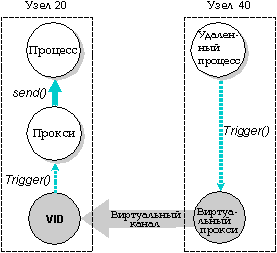
На удаленном узле создается виртуальный прокси, который ссылается на локальный прокси.
Имейте в виду, что на вызывающем узле виртуальный канал создается автоматически посредством функции qnx_proxy_rem_attach().
Отключение виртуальных каналов
Процесс может утратить возможность связи по установленному VC в результате различных причин:
Любая из этих причин может помешать передаче сообщений по VC. Необходимо выявлять такие ситуации с тем, чтобы приложения могли предпринять корректирующие действия, либо корректно завершить свое выполнение. Если это не будет сделано, то ценные ресурсы могут оставаться без необходимости постоянно занятыми.
Менеджер процессов на каждом узле проверяет целостность VC на своем узле. Он делает это следующим образом:
Для установки параметров, связанных с данной проверкой целостности VC, используйте утилиту netpoll.
Другой распространенной формой синхронизации процессов являются семафоры. Операции "сигнализации" (sem_post()) и "ожидания" (sem_wait()) позволяют управлять выполнением процессов, переводя их в состояние ожидания либо выводя из него. Операция сигнализации увеличивает значение семафора на единицу, а операция ожидания уменьшает его на единицу.
При положительном значении семафора, при выполнении операции ожидания, процесс не блокируется. В противном случае операция ожидания блокирует процесс до тех пор, пока какой-либо другой процесс не выполнит операцию сигнализации. Допускается выполнение операции сигнализации один или более раз перед выполнением операции ожидания - это позволит одному или нескольким процессам выполнить операцию ожидания, не блокируясь.
Важное отличие между семафорами и другими примитивами синхронизации заключается в том, что семафоры "асинхронно безопасны" и могут использоваться обработчиками сигналов. Если требуется, чтобы обработчик сигнала выводил процесс из состояния ожидания, то семафоры являются правильным выбором.
Когда принимаются решения по диспетчеризации
Планировщик Микроядра принимает решение по диспетчеризации:
В QNX каждому из процессов присваивается приоритет. Планировщик выбирает для выполнения следующий процесс, находящийся в состоянии READY, в соответствии с его приоритетом. (Программа в состоянии READY - это программа, которая способна использовать ЦП). Для выполнения выбирается процесс с наивысшим приоритетом.
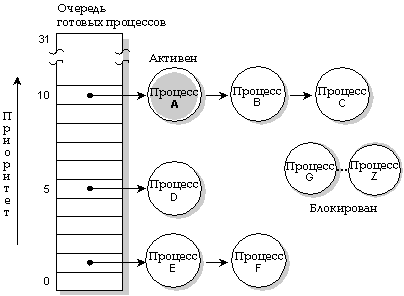
В очереди шесть процессов (A-F), готовых к выполнению и находящихся в состоянии READY. Остальные процессы (G-Z) блокированы. В данный момент выполняется процесс A. Процессы A, B и C имеют наивысший приоритет, поэтому будут разделять центральный процессор в соответствии с алгоритмом диспетчеризации для выполняемого процесса.
Приоритеты, присваиваемые процессам, находятся в диапазоне от 0 (наименьший) до 31 (наивысший). Уровень приоритета по умолчанию для создаваемого процесса наследуется от его родителя; для приложений, запускаемых командным процессором, приоритет обычно равен 10.
| Если вы хотите: | Используйте функцию языка СИ: |
|---|---|
| Определить приоритет процесса | getprio() |
| Установить приоритет для процесса | setprio() |
Чтобы удовлетворить потребность различных приложений, QNX предлагает три метода диспетчеризации:
Каждый процесс в системе может выполняться, используя любой из этих методов. Они действуют применительно к каждому отдельному процессу, а не применительно ко всем процессам на узле.
Помните, что эти методы диспетчеризации применимы, только когда два или более процесса с одинаковым приоритетом находятся в состоянии READY (т.е. эти процессы непосредственно конкурируют друг с другом). Если процесс с более высоким приоритетом переходит в состояние READY, то он немедленно вытесняет все процессы с более низким приоритетом.
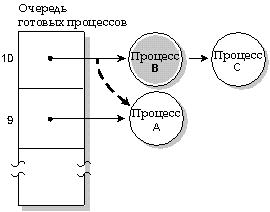
На следующей диаграмме три процесса с одинаковым приоритетом находятся в состоянии READY. Если процесс А блокируется, то выполняется процесс B.
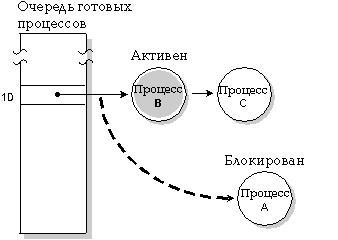
Процесс A блокируется, процесс B выполняется.
Метод диспетчеризации процесса наследуется от его родительского процесса, однако, затем этот метод может быть изменен.
| Если вы хотите: | Используйте функцию языка Си: |
|---|---|
| Определить метод диспетчеризации для процесса | getscheduler() |
| Установить метод диспетчеризации для процесса | setscheduler() |
При FIFO диспетчеризации процесс продолжает выполнение пока не наступит момент, когда он:
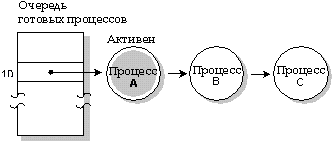
FIFO диспетчеризация. Процесс А выполняется до тех пор, пока не блокируется.
Два процесса, которые выполняются с одним и тем же приоритетом, могут использовать метод FIFO для организации взаимоисключающего доступа к разделяемому (т.е. совместно используемому) ресурсу. Ни один из них не будет вытеснен другим во время своего выполнения. Так, например, если они совместно используют сегмент памяти, то каждый из этих двух процессов может обновлять данные в этом сегменте, не прибегая к использованию какого-либо способа синхронизации (например, семафора).
При карусельной диспетчеризации процесс продолжает выполнение, пока не наступит момент, когда он:
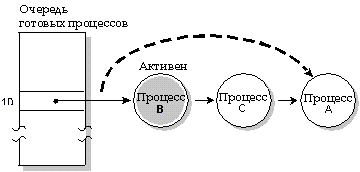
Карусельная диспетчеризация. Процесс А выполняется до тех пор, пока он не использовал свой квант времени; затем выполняется следующий процесс, находящийся в состоянии READY (процесс B).
Квант времени - это интервал времени, выделяемый каждому процессу. После того, как процесс использовал свой квант времени, управление передается следующему процессу, который находится в состоянии READY и имеет такой же уровень приоритета. Квант времени равен 50 миллисекундам.
| За исключением квантования времени, карусельная диспетчеризация идентична FIFO-диспетчеризации. |
При адаптивной диспетчеризации процесс ведет себя следующим образом:
Адаптивная диспетчеризация. Процесс А использовал свой квант времени; его приоритет снизился на 1. Выполняется следующий процесс в состоянии READY (процесс B).
Вы можете использовать адаптивную диспетчеризацию в тех случаях, когда процессы, производящие интенсивные вычисления, выполняются в фоновом режиме одновременно с интерактивной работой пользователей. Вы обнаружите, что адаптивная диспетчеризация дает производящим интенсивные вычисления процессам достаточный доступ к ЦП и в то же время сохраняет быстрый интерактивный отклик для других процессов.
Адаптивная диспетчеризация является методом диспетчеризации, использующимся по умолчанию для программ, запускаемых командным интерпретатором.
В QNX обмен данными между процессами в большинстве случаев организован с использованием модели клиент/сервер. Серверы выполняют некоторые сервисные функции, а клиенты, посылая сообщение серверу, запрашивают эти услуги. Как правило, серверы более надежны и жизнеспособны, чем клиенты.
Количество клиентов обычно больше, чем серверов. Как следствие этого, принято запускать сервер с приоритетом более высоким, чем у любого из его клиентов. Может использоваться любой из трех рассмотренных выше методов диспетчеризации, но, наверное, самым распространенным является карусельный.
Если клиент с низким уровнем приоритета посылает сообщение серверу, то его запрос выполняется под более высоким уровнем приоритета, тем, который имеется у сервера. Это косвенным образом повышает приоритет клиента, т.к. именно его запрос заставил сервер выполняться.
Пока для выполнения запроса серверу достаточно короткого промежутка времени, проблем обычно не возникает. Если же выполнение запроса занимает у сервера более продолжительное время, то клиент с низким приоритетом может неблагоприятно повлиять на выполнение других процессов, приоритеты которых выше, чем у клиента, но ниже, чем у сервера.
Чтобы решить эту дилемму, сервер может поставить свой приоритет в зависимость от приоритета того клиента, чей запрос он выполняет. Когда сервер получает сообщение, приоритет будет установлен таким же, как у клиента. Обратите внимание, что изменился только приоритет сервера - его алгоритм диспетчеризации остается неизменным. Если во время выполнения запроса сервер получает другое сообщение, и приоритет нового клиента выше, чем у сервера, то приоритет сервера повышается. Фактически, новый клиент "заряжает" сервер до своего уровня приоритета, позволяя ему закончить выполнение текущего запроса и приступить к обработке запроса нового клиента. Если этого не делать, то фактически приоритет нового клиента понизится, пока он блокирован на сервере с низким приоритетом.
Если вы выбрали клиент-управляемый приоритет для своего сервера, вам следует также запросить доставку сообщений в порядке убывания приоритетов (в противоположность хронологическому).
Чтобы установить клиент-управляемый приоритет, используйте функцию Си qnx_pflags() следующим образом:
qnx_pflags(~0, _PPF_PRIORITY_FLOAT
| _PPF_PRIORITY_REC, 0, 0);
Как бы мы этого не хотели, компьютеры не являются бесконечно быстрыми. Для системы реального времени жизненно важно, чтобы такты работы ЦП не расходовались зря. Также очень важно свести к минимуму время, которое проходит с момента наступления внешнего события до начала выполнения кода программы, ответственной за обработку данного события. Это время называется задержкой.
В QNX системе встречается несколько видов задержек.
Задержка прерывания - это интервал времени между аппаратным прерыванием и выполнением первой команды программного обработчика прерывания. QNX практически все время оставляет прерывания полностью разрешенными, поэтому задержка прерывания, как правило, не существенна. Однако некоторые критические фрагменты кода требуют, чтобы прерывания были временно запрещены. Максимальная продолжительность такого запрета обычно определяет худший случай задержки прерывания - в QNX это очень небольшая величина.
Следующая диаграмма иллюстрирует случай, когда аппаратное прерывание обрабатывается в установленном обработчиком прерывании. Обработчик прерывания либо просто выполнит команду возврата, либо при возврате запустит прокси.
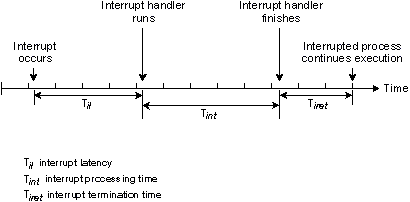
Обработчик прерывания просто завершается.
Задержка прерывания (Til) на приведенной выше диаграмме отражает минимальную задержку - случай, когда прерывания были полностью разрешены в момент, когда произошло прерывание. В худшем случае задержка прерывания составит это время плюс наибольшее время, в течение которого QNX или выполняющийся процесс запрещает прерывания ЦП.
Следующая таблица содержит типичные значения задержки прерывания (Tqqq?1ilqqq?0) для разных процессоров:
| Задержка прерывания (Til): | Процессор: |
|---|---|
| 3.3 микросекунды | 166 МГц Pentium |
| 4.4 микросекунды | 100 МГц Pentium |
| 5.6 микросекунды | 100 МГц 486DX4 |
| 22.5 микросекунды | 33 МГц 386EX |
В некоторых случаях обработчик аппаратного прерывания низкого уровня должен передать управление процессу более высокого уровня. В этом случае обработчик прерывания перед выполнением команды "возврат" запускает прокси. Здесь имеет место второй вид задержки - задержка диспетчеризации, - с которой также надо считаться.
Задержка диспетчеризации - это время между завершением работы обработчика прерывания и выполнением первой команды процесса-драйвера. Это время, необходимое для сохранения контекста, выполняющегося в данный момент времени процесса, и восстановления контекста требуемого драйвера. В QNX это время также невелико, хотя и больше задержки прерывания.
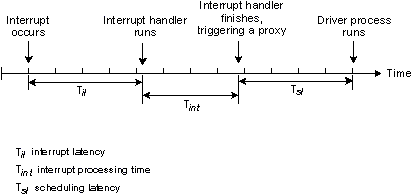
Обработчик прерывания завершает работу и запускает прокси.
Важно отметить, что обработка большинства прерываний завершается без запуска прокси. В большинстве случаев обработчик прерывания сам может выполнить все необходимые действия. Запуск прокси, чтобы "разбудить" драйвер, процесс более высокого уровня, происходит только при наступлении важного события. Например, обработчик прерывания для драйвера последовательного порта при каждом прерывании "регистр передачи свободен" будет передавать один байт данных и запустит процесс более высокого уровня (Dev) только тогда, когда выходной буфер, наконец, опустеет.
Следующая таблица содержит типичные значения задержки диспетчеризации (Tsl) для разных процессоров:
| Задержка диспетчеризации (Tsl): | Процессор: |
|---|---|
| 4.7 микросекунды | 166 МГц Pentium |
| 6.7 микросекунды | 100 МГц Pentium |
| 11.1 микросекунды | 100 МГц 486DX4 |
| 74.2 микросекунды | 33 МГц 386EX |
Так как архитектура микрокомпьютеров позволяет назначать приоритеты аппаратным прерываниям, то прерывания с более высоким приоритетом могут вытеснять прерывания с меньшим приоритетом.
Этот механизм полностью поддерживается в QNX. Выше были рассмотрены простейшие - и наиболее типичные - ситуации, когда происходит только одно прерывание. Практически такой же расчет времени справедлив для прерывания с наивысшим приоритетом. При рассмотрении наихудшего случая для прерывания с низким приоритетом необходимо учитывать время обработки всех прерываний более высокого уровня, т.к. в QNX прерывание с более высоким приоритетом вытеснит прерывание с меньшим приоритетом.
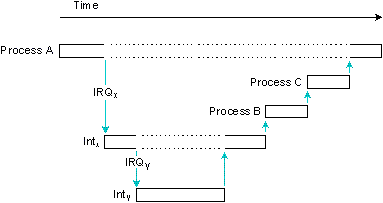
Выполняется процесс A. Прерывание IRQx вызывает выполнение обработчика прерывания Intx, который вытесняется IRQy и его обработчиком Inty. Inty запускает прокси, вызывающее выполнение процесса B, а Intx запускает прокси, вызывающее выполнение процесса C.
Эта глава охватывает следующие темы:
Обязанности Менеджера процессов
Менеджер процессов тесно взаимодействует с Микроядром, чтобы обеспечить услуги, составляющие сущность операционной системы. Хотя он и является единственным процессом, который использует то же адресное пространство, что и Микроядро, Менеджер процессов выполняется как истинный процесс. И он, как и все остальные процессы, подвергается диспетчеризации со стороны Ядра и использует предоставляемые Микроядром примитивы передачи сообщений для связи с другими процессами в системе.
Менеджер процессов отвечает за создание новых процессов в системе и за управление основными ресурсами, связанными с процессом. Все эти услуги предоставляются посредством сообщений. Так, например, если процесс хочет породить новый процесс, он делает это, посылая сообщение с указанием атрибутов создаваемого процесса. Обратите внимание, что т.к. сообщения передаются по сети, вы можете легко создать процесс на другом узле сети, послав сообщение Менеджеру процессов на этом узле.
QNX поддерживают три примитива создания процесса:
Примитивы fork() и exec() определены стандартом POSIX, а примитив spawn() реализован только в QNX.
Примитив fork() создает новый процесс, который является точной копией вызвавшего его процесса. Новый процесс использует тот же самый код, что и породивший его процесс, и наследует копию всех данных родительского процесса.
Примитив exec() заменяет вызвавший процесс новым. После успешного вызова exec() возврата не происходит, т.к. образ вызывающего процесса заменяется образом нового процесса. Обычной практикой в POSIX-системах для создания нового процесса - без удаления вызывающего процесса - является сначала вызов fork(), а затем вызов exec() из порожденного процесса.
Примитив spawn() создает новый процесс как потомок вызывающего процесса. С его помощью можно избежать вызовов fork() и exec(), используя более быстрый и эффективный способ создания новых процессов. В отличие от fork() и exec(), которые по своей природе выполняются на том же самом узле, что и вызывающий процесс, примитив spawn() может создавать процессы на любом узле сети.
Когда с помощью одного из трех рассмотренных выше примитивов задается новый процесс, он наследует многое из своего окружения от родителя. Это сведено в следующую таблицу:
| Наследуемый параметр | fork() | exec() | spawn() |
|---|---|---|---|
| Идентификатор процесса | нет | да | нет |
| Открытые файлы | да | по выбору* | по выбору |
| Блокировка файлов | нет | да | нет |
| Ожидающие сигналы | нет | да | нет |
| Маска сигналов | да | по выбору | по выбору |
| Игнорируемые сигналы | да | по выбору | по выбору |
| Обработчики сигналов | да | нет | нет |
| Переменные окружения | да | по выбору | по выбору |
| Идентификатор сеанса | да | да | по выбору |
| Группа процесса | да | да | по выбору |
| Реальные UID, GID | да | да | да |
| Эффективные UID, GID | да | по выбору | по выбору |
| Текущий рабочий каталог | да | по выбору | по выбору |
| Маска создания файлов | да | да | да |
| Приоритет | да | по выбору | по выбору |
| Алгоритм диспетчеризации | да | по выбору | по выбору |
| Виртуальные каналы | нет | нет | нет |
| Символьные имена | нет | нет | нет |
| таймеры реального времени | нет | нет | нет |
*по выбору: вызывающий процесс может по необходимости выбрать - да или нет.
Процесс проходит через четыре стадии:
Создание нового процесса состоит из присвоения новому процессу идентификатора (ID) процесса и подготовки информации, которая определяет окружение нового процесса. Большая часть этой информации наследуется от родительского процесса (смотри раздел "Наследование").
Загрузка образа процесса производится нитью загрузчика. Код загрузчика находится в Менеджере процессов, но нить выполняется под ID нового процесса. Это позволяет Менеджеру процессов обрабатывать и другие запросы во время загрузки программы.
После того, как код программы загружен, процесс готов к выполнению; он начинает конкурировать с остальными процессами за ресурсы ЦП. Заметьте, что все процессы выполняются параллельно со своими родителями. Кроме того, смерть родительского процесса не означает автоматическую смерть его дочерних процессов.
Процесс завершается одним из двух способов:
Завершение включает две стадии:
Если родительский процесс не вызвал wait() или waitpid(), то дочерний процесс становится "зомби" и не будет завершен, пока родительский процесс не вызовет wait() или не завершит выполнение. (Если вы не хотите, чтобы процесс ждал смерти дочерних процессов, вы должны либо установить _SPAWN_NOZOMBIE флаг функциями qnx_spawn() или qnx_spawn_options(), либо установить действие SIG_IGN для сигнала SIGCHLD посредством функции signal(). Таким образом, дочерние процессы не будут становиться зомби после смерти.)
Родительский процесс может ждать смерти дочернего процесса, запущенного на удаленном узле. Если родитель процесса-зомби умирает, то зомби освобождается.
Если запущена утилита dumper и процесс завершается в результате получения сигнала, то генерируется дамп памяти. Вы можете затем исследовать его с помощью отладчика.
Процесс всегда находится в одном из следующих состояний:
| Для получения более полной информации о блокированном состоянии обратитесь к главе "Микроядро". |
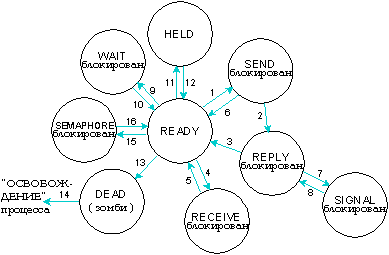
Возможные состояния процесса в QNX.
Показаны следующие переходы:
Определение состояний процесса
Чтобы определить состояние конкретного процесса из командного интерпретатора (Shell), используйте утилиты ps и sin (внутри приложений используйте функцию qnx_psinfo()).
Чтобы определить состояние операционной системы в целом из командного интерпретатора (Shell), используйте утилиту sin (внутри приложений используйте функцию qnx_osinfo()).
Утилита ps определена стандартом POSIX; ее использование в командных файлах может быть переносимым в другие системы. Утилита sin, напротив, уникальна для QNX; она дает вам полезную информацию, специфическую для QNX, которую вы не можете получить, используя утилиту ps.
QNX стимулирует разработку приложений, которые разбиты на несколько взаимодействующих процессов. Такое приложение, которое существует как группа взаимодействующих процессов, имеет большие возможности распараллеливания и может быть распределено по сети для лучшей производительности.
Однако разделение приложений на взаимодействующие процессы требует ряда специальных соображений. Чтобы взаимодействующие процессы могли установить связь между собой, они должны иметь возможность определить идентификаторы друг друга. Например, допустим, что имеется сервер базы данных, который может обслуживать произвольное количество клиентов. Клиенты могут запускаться и прекращать работу в любое время, однако сервер всегда остается доступным. Как процессы-клиенты узнают идентификатор процесса-сервера базы данных с тем, чтобы послать ему сообщение?
В QNX процессы могут присваивать себе символьные имена. В контексте одного узла процесса могут зарегистрировать эти имена у Менеджера процессов на том узле, на котором они выполняются. Остальные процессы могут затем запросить у Менеджера процессов идентификатор процесса, ассоциированный с определенным именем.
Ситуация становится более сложной, если мы рассмотрим сеть, в которой сервер обслуживает клиентов, находящихся на различных узлах. Поэтому в QNX предусмотрена поддержка как глобальных, так и локальных имен. Глобальные имена определены для всей сети, в то время как локальные имена определены только для того узла, на котором они зарегистрированы. Глобальные имена начинаются с косой черты (/). Например:
| qnx/fsys | локальное имя |
| company/xyz | локальное имя |
| /company/xyz | глобальное имя |
| Мы рекомендуем вам использовать название вашей компании в качестве префикса для всех регистрируемых имен, чтобы избежать конфликтов имен между программами разных производителей. |
Чтобы сделать возможным использование глобальных имен, хотя бы на одном узле сети должен быть запущен процесс, известный как определитель имен (утилита nameloc). Этот процесс ведет учет всех зарегистрированных глобальных имен.
В каждый момент времени в сети могут быть запущены до десяти определителей имен. Каждый хранит идентичные копии всех активных глобальных имен. Такая избыточность гарантирует нормальное функционирование сети, даже если один или несколько узлов, обеспечивающих определение имен, выйдут из строя одновременно.
Чтобы зарегистрировать имя, процесс сервер использует функцию Си qnx_name_attach(). Чтобы определить процесс по имени, процесс клиент использует функцию Си qnx_name_locate().
В QNX исчисление времени основывается на системном таймере, поддерживаемом операционной системой. Таймер содержит текущее значение Координированного Всемирного Времени (UTC) относительно 0 часов, 0 минут, 0 секунд, 1 января 1970 года. Чтобы определить местное время, функции исчисления времени используют переменную окружения TZ (которая описывается в книге Руководство пользователя).
Простые средства отсчета времени
Командные файлы и процессы могут делать паузу на определенное количество секунд, используя простые средства отсчета времени. В командных файлах для этой цели используется утилита sleep; в процессах используется функция Си sleep(). Также может использоваться функция delay(), которой в качестве аргумента передается длина интервала времени в миллисекундах.
Более сложное средство отсчета времени
Кроме того, процесс может создавать таймеры, устанавливать их на определенный интервал времени и удалять таймер. Эти средства отсчета времени основываются на спецификации POSIX Std 1003.4/Draft 9.
Процесс может создать один или больше таймеров. Эти таймеры могут быть любых типов и в любом сочетании. С учетом конфигурируемого ограничения общего числа таймеров, поддерживаемых операционной системой (смотри Proc в Описание утилит). Для создания таймера используйте функцию timer_create().
При установке таймеров вы можете использовать один из двух типов интервалов времени:
Вы также можете создать таймер, периодически срабатывающий с заданным интервалом времени. Например, вы установили таймер таким образом, чтобы он сработал завтра в 9 часов утра. Вы можете задать, чтобы после этого он срабатывал каждые 5 минут.
Вы также можете установить временной интервал для существующего таймера. Результат будет зависеть от типа интервала времени:
| Чтобы установить таймер: | Используйте функцию: |
|---|---|
| Абсолютный или относительный интервал | timer_settime() |
Чтобы удалить таймер, используйте функцию Си timer_delete().
Вы можете установить разрешение для таймера с помощью утилиты ticksize или функции qnx_timerperiod(). Вы можете настраивать разрешение от 500 микросекунд до 50 миллисекунд.
Чтобы узнать оставшийся от таймера интервал или проверить, не был ли таймер удален, используйте функцию Си timer_gettime().
Обработчики прерываний обслуживают систему аппаратных прерываний компьютера - они реагируют на аппаратные прерывания и осуществляют передачу данных между компьютером и внешними устройствами на низком уровне.
Обработчики прерываний физически являются частью стандартного процесса QNX (например, драйвер), но они всегда выполняются асинхронно по отношению к процессу, в который они включены.
Обработчик прерываний:
Несколько процессов могут обрабатывать одно и то же прерывание (если это поддерживается аппаратно). Когда происходит физическое прерывание, все обработчики прерываний будут по очереди получать управление. Не должно делаться никаких предположений относительно порядка, в котором будут вызываться обработчики прерываний, разделяющие одно и то же прерывание.
| Если вы хотите: | Используйте функцию: |
|---|---|
| Установить обработчик прерывания | qnx_hint_attach() |
| Удалить обработчик прерывания | qnx_hint_detach() |
Обработчики прерывания таймера
Вы можете установить обработчик прерывания непосредственно для системного таймера таким образом, что обработчик будет вызываться по каждому прерыванию таймера. Чтобы установить период, вы можете использовать утилиту ticksize.
Вы можете также установить обработчик прерывания для отмасштабированного прерывания таймера, которое будет происходить каждые 50 миллисекунд, независимо от tick size. Эти таймеры предлагают низкоуровневую альтернативу POSIX 1003.4 таймерам.
Эта глава охватывает следующие темы:
Пространство имен ввода/вывода
Ресурсы ввода/вывода (I/O, от английского Input/Output) в QNX не встроены внутрь Микроядра. Процессы обслуживающие ввод/вывод запускаются динамически во время работы системы. Так как файловая система QNX является необязательным элементом, то пространство путей (полных имен файлов и каталогов) не встроено внутрь файловой системы, в отличие от большинства монолитных систем.
В QNX пространство имен путей разделено на области полномочий. Любой процесс, выполняющий файл-ориентированное обслуживание ввода/вывода, должен зарегистрировать у Менеджера процессов свой префикс, определяя часть пространства имен, которое он хочет контролировать (т.е. область своих полномочий). Эти префиксы составляют дерево префиксов, которое хранится в памяти на каждом компьютере под управлением QNX.
Префиксы менеджера ввода/вывода
Когда процесс открывает файл, то полное имя файла сопоставляется с деревом префиксов с тем, чтобы отправить запрос open() к соответствующему менеджеру ресурсов ввода/вывода. Например, Менеджер устройств (Dev) обычно регистрирует префикс /dev. Если процесс вызывает open() с аргументом /dev/xxx, то совпадет префикс /dev и open() будет направлен к Dev (его владельцу).
Дерево префиксов может содержать частично перекрывающиеся области полномочий. В этом случае ищется наиболее длинное совпадение. Например, предположим, что есть три зарегистрированных префикса:
| / | дисковая файловая система (Fsys) |
| /dev | система символьных устройств (Dev) |
| /dev/hd0 | дисковый том без разделов (Fsys) |
Менеджер файловой системы зарегистрировал два префикса, один для смонтированной файловой системы QNX (т.е. /) и один для блок-ориентированного файла, который представляет весь физический жесткий диск (т.е. /dev/hd0). Менеджер устройств зарегистрировал единственный префикс. Следующая таблица иллюстрирует правило наиболее длинного совпадения при разборе имен путей.
| Имя пути: | Совпадает: | Относится к: |
|---|---|---|
| /dev/con1 | /dev | Dev |
| /dev/hd0 | /dev/hd0 | Fsys |
| /usr/dtdodge/test | / | Fsys |
Дерево префиксов хранится как список префиксов, разделенных двоеточиями, следующим образом:
prefix=pid,unit:prefix=pid,unit:prefix=pid,unit
где pid - это ID процесса менеджера ресурсов I/O, а unit - это один символ, используемый менеджером для нумерации префиксов, которыми он владеет. В приведенном выше примере, если Fsys был бы процессом 3 и Dev был бы процессом 5, то дерево префиксов выглядело бы как:
/dev/hd0=3,a:/dev=5,a:/=3,e
| Если вы хотите: | Используйте: |
|---|---|
| Показать дерево префиксов | Утилиту prefix |
| Получить дерево префиксов внутри программы на языке Си | Функцию qnx_prefix_query() |
QNX поддерживают концепцию сетевого корня, которая позволяет сопоставлять имя пути с деревом префиксов на конкретном узле. Для обозначения узла имя пути начинается с двух косых черт, за которыми следует номер узла. Это также позволяет вам легко получать доступ к файлу и устройству, которые лежат за пределами пространства путей вашего узла. Например, в типичной сети QNX возможны следующие имена путей:
| /dev/ser1 | локальный последовательный порт |
| //10/dev/ser1 | последовательный порт в узле 10 |
| //0/dev/ser1 | локальный последовательный порт |
| //20/usr/dtdodge/test | файл на узле 20 |
Заметьте, что //0 всегда указывает на локальный узел
Когда программа выполняется на удаленном узле, вы обычно хотите, чтобы она рассматривала имена путей в контексте пространства имен своего узла. Например, эта команда:
//5 ls /
которая запускает утилиту ls на узле 5, возвратит то же самое, что и:
ls /
запускаемая на своем узле. В обоих случаях "/" будет соотноситься с деревом префиксов на вашем узле, а не на узле 5. В противном случае, можно представить себе беспорядок, который мог бы возникнуть, если бы префикс "/" рассматривался своим как для узла 5, так и для своего узла: выбирались бы одновременно файлы из разных файловых систем!
Чтобы правильно интерпретировать имена путей, каждый процесс имеет сетевой корень по умолчанию, который определяет, дерево префиксов какого узла будет использоваться для разбора любых имен путей, начинающихся с одиночной косой черты ("/"). Когда разбирается имя пути, начинающееся с одиночной косой черты, то оно предваряется сетевым корнем по умолчанию. Например, если процесс имеет сетевой корень по умолчанию //9, тогда:
/usr/home/luc
будет разбираться, как:
//9/usr/home/luc
что может быть интерпретировано, как "разобрать путь /usr/home/luc, используя дерево префиксов 9-го узла".
Сетевой корень по умолчанию наследуется процессами при их создании и соответствует локальному узлу, на котором запускается система. Например, допустим, что вы работаете на узле 9, находясь в командном интерпретаторе, для которого сетевой корень по умолчанию установлен как узел 9 (весьма типичный случай). Если вы выполните команду:
ls /
команда унаследует сетевой корень по умолчанию //9, и в результате вы получите:
ls //9/
Подобно тому, если бы вы ввели команду:
//5 ls /
Вы запустили команду ls на узле 5, но она по-прежнему унаследует сетевой корень по умолчанию //9, поэтому в результате вы опять получите ls //9/. В обоих случаях имя пути разбирается относительно одного и того же пространства имен.
| Если вы хотите: | Используйте: |
|---|---|
| Получить текущий сетевой корень по умолчанию | Функцию qnx_prefix_getroot() |
| Установить сетевой корень по умолчанию | Функцию qnx_prefix_setroot() |
| Запустить программу с новым сетевым корнем по умолчанию | Утилиту on |
Если запущено одновременно несколько процессов, они не обязательно имеют один и тот же сетевой корень по умолчанию, даже если они выполняются на одном и том же узле. К примеру, один из процессов мог унаследовать сетевой корень по умолчанию от родительского процесса на каком-либо другом узле сети, либо его сетевой корень по умолчанию мог быть в явном виде задан родительским процессом.
При передаче имени пути между процессами, чьи сетевые корни могут отличаться (например, передавая файл спулеру для печати), вы должны добавить сетевой корень в начало имени пути, прежде чем передать путь другому процессу. Если вы уверены, что посылающий процесс и получатель имеют один и тот же сетевой корень по умолчанию (или имя пути уже начинается с //узел/), то вы можете опустить этот шаг.
Мы рассмотрели префиксы, которые регистрируются менеджерами ресурсов I/O. Вторая форма префикса известна как псевдоним префикса, это простая подстановка строки вместо искомого префикса. Псевдоним префикса имеет форму:
prefix=строка-заменитель
Например, вы работаете на машине, у которой нет локальной файловой системы (поэтому нет и процесса, который бы отвечал за "/"). Однако, файловая система имеется на другом узле (допустим, 10), и вы хотите ее использовать как "/". Вы можете сделать это с помощью следующего псевдонима префикса:
/=//10/
Это приведет к тому, что ведущая косая черта (/) будет заменяться на префикс //10/. Например, путь /usr/dtdodge/test будет заменен следующим:
//10/usr/dtdodge/test
Это новое имя пути будет снова сравниваться с деревом префиксов; на этот раз будет использоваться уже дерево префиксов 10 узла, т.к. имя пути начинается с //10. Это приведет к Менеджеру файловой системы на узле 10, которому и будет направлен запрос, например, open(). С помощью всего лишь нескольких символов этот псевдоним позволил нам обращаться к удаленной файловой системе как к локальной.
Для того чтобы выполнить перенаправление, не обязательно запускать локальную файловую систему. Дерево префиксов для бездисковой рабочей станции может выглядеть примерно так:
/dev=5,a:/=//10/
При таком дереве префиксов номера путей, начинающихся с /dev, будут направляться к локальному менеджеру символьных устройств, в то время как запросы с любыми другими именами путей, будут направляться к удаленной файловой системе.
Вы также можете использовать псевдонимы создания специальных имен устройств. Например, если спулер печати запущен на узле 20, то вы можете создать для него локальный псевдоним следующим образом:
/dev/printer=//20/dev/spool
Любой запрос на открытие локального принтера /dev/printer будет направляться по сети к реальному спулеру. Аналогичным образом, если не существует локального дисковода для гибких дисков, псевдоним для удаленного дисковода на узле 20 может иметь вид:
/dev/fd0=//20/dev/fd0
В обоих рассмотренных выше случаях можно не использовать перенаправление с помощью псевдонима, а обращаться непосредственно к удаленному ресурсу следующим образом:
//20/dev/spool ИЛИ //20/dev/fd0
Путь не обязательно должен начинаться с одной или двух косых черт. В таких случаях путь считается относительным по отношению к текущему рабочему каталогу. QNX хранит текущий рабочий каталог в виде строки символов. Относительные пути преобразуются в полные сетевые имена пути добавлением текущего рабочего каталога в начало относительного пути.
Учтите, что результат зависит от того, начинается ли текущий рабочий каталог с одинарной косой черты, либо с сетевого корня.
Если текущий рабочий каталог начинается с двойной косой черты (сетевого корня), он называется определенным и привязан к пространству имен указанного узла. В противном случае, если он начинается с одинарной косой черты, то в начало добавляется сетевой корень по умолчанию.
Например, эта команда:
cd //18/
является примером первой (определенной) формы и привязывает последующие разборы относительных путей к узлу 18, независимо от того, какое значение сетевого корня по умолчанию. Выполнив затем команду cd dev, вы попадете в //18/dev.
С другой стороны, такая команда:
cd /
является примером второй формы, когда сетевой корень по умолчанию влияет на разбор относительного пути. Например, если сетевой корень по умолчанию //9, тогда, выполнив команду cd dev, вы попадете в //9/dev. Так как текущий рабочий каталог не начинается с указания узла, то сетевой корень по умолчанию добавляется для получения полного сетевого пути.
Это на самом деле не так сложно, как может показаться. Обычно сетевые корни (//узел/) не указываются, и все, что вы делаете, просто работает внутри пространства имен вашего узла (определяемого вашим сетевым корнем по умолчанию). Большинство пользователей, войдя в систему, принимают нормальный сетевой корень по умолчанию (т.е. пространство имен их собственного узла) и работают внутри этой среды.
В некоторых традиционных UNIX системах команда cd (сменить директорию) модифицирует заданный путь, если он содержит символьные ссылки. Как результат, путь к новому текущему рабочему каталогу - который можно посмотреть командой pwd, может отличаться от того, который был задан в команде cd.
В QNX, однако, cd не изменяет путь - за исключением сокращенных ссылок "..". Например:
cd /usr/home/luc/test/../doc
установит текущий рабочий каталог /usr/home/luc/doc, даже если некоторые элементы этого пути являются символическими связями.
Более подробную информацию о символических связях можно получить в главе "Менеджер файловой системы".